![]() 在 GitHub 上执行或查看/下载此笔记本
在 GitHub 上执行或查看/下载此笔记本
动态批处理:它是什么以及为什么有时是必要的
将示例批量处理在一起是至关重要的优化,可以显著加速训练过程。这与跨多个 GPU 的分布式训练相结合,使得在大型数据集上训练参数量庞大的模型可以在几天而不是几个月内完成。
传统方法是使用固定批量大小将示例分组。然而,当每个输入大小不同时(这在音频或自然语言处理 (NLP) 应用中很常见),就需要对批次中的每个示例进行填充,以匹配该批次中最大示例的大小。
虽然这是一种常见做法,但当示例长度差异很大时,它会引入潜在的低效。在音频和 NLP 应用等场景中,很大一部分计算是在填充值上进行的,这会导致计算浪费。为了解决这个问题,动态批处理变得必不可少,它允许在各种机器学习任务中更高效、更节省资源地处理变长序列。
为了说明这一点,例如,我们来看一下 MiniLibriSpeech,它是 LibriSpeech 的一个子集。让我们从 data-io 教程下载这个数据集和其他工具,该教程使用了相同的数据。
%%capture
# here we download the material needed for this tutorial: images and an example based on mini-librispeech
!wget https://www.dropbox.com/s/b61lo6gkpuplanq/MiniLibriSpeechTutorial.tar.gz?dl=0
!tar -xvzf MiniLibriSpeechTutorial.tar.gz?dl=0
# downloading mini_librispeech dev data
!wget https://www.openslr.org/resources/31/train-clean-5.tar.gz
!tar -xvzf train-clean-5.tar.gz
接下来,我们安装 speechbrain
%%capture
# Installing SpeechBrain via pip
BRANCH = 'develop'
!python -m pip install git+https://github.com/speechbrain/speechbrain.git@$BRANCH
现在,让我们看看此数据集中每个音频的长度以及它们的分布情况。
我们可以使用 torchaudio 绘制此数据集中每个音频长度的直方图
import matplotlib.pyplot as plt
import torchaudio
import numpy
import glob
import os
# fetching all flac files in MiniLibriSpeech
all_flacs = glob.glob(os.path.join("/content/LibriSpeech/train-clean-5", "**/*.flac"), recursive=True)
print("Number of audio files in MiniLibriSpeech train-clean-5: ", len(all_flacs))
# step-by-step
# collect durations
all_durations = numpy.zeros(len(all_flacs))
for i, audio in enumerate(all_flacs):
wav_meta = torchaudio.info(audio)
all_durations[i] = wav_meta.num_frames / wav_meta.sample_rate
# plot histogram
_ = plt.hist(all_durations, bins='auto')
plt.title("MiniLibriSpeech: train-clean-5")
plt.xlabel("Duration (in s)")
plt.ylabel("# audios")
plt.show()
Number of audio files in MiniLibriSpeech train-clean-5: 1519
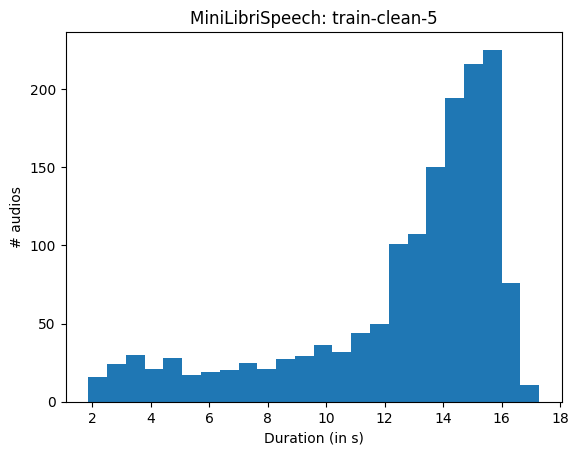
我们可以看到大多数文件的长度在 14 到 16 秒之间。此外,文件长度差异很大。因此,如果我们不采用任何特定策略随机采样一定数量的示例(例如 8 个),对其进行填充并批量处理,最终会得到大量的填充值。
这样,我们将在填充值上浪费大量计算。
我们可以尝试有效地计算在使用固定批量大小时遍历整个数据集期间属于填充的总样本数。
我们在这里遵循 SpeechBrain 数据准备的最佳实践。我们将所有示例解析到一个 .json 文件中,这样解析只发生一次,而不是在每个新实验开始时都进行。事实上,在网络存储或慢速物理硬盘上解析许多小文件可能需要很多时间。
# prepare LibriSpeech dataset using pre-made, downloaded parse_data.py script from
# the data-io tutorial available here: https://docs.speechbrain.cn/en/latest/tutorials/basics/data-loading-pipeline.html
from parse_data import parse_to_json
parse_to_json("/content/LibriSpeech/train-clean-5")
# this produced a manifest data.json file:
我们可以简要查看每个 .json 文件。我们特别关注 length 字段,其中包含数据集中每个音频的样本长度。
!tail -n 20 data.json
},
"4640-19188-0038": {
"file_path": "/content/LibriSpeech/train-clean-5/4640/19188/4640-19188-0038.flac",
"words": "THE FIFTH MAN WAS SAVED",
"spkID": "speaker_4640",
"length": 41200
},
"4640-19188-0005": {
"file_path": "/content/LibriSpeech/train-clean-5/4640/19188/4640-19188-0005.flac",
"words": "COME SAID HE YOU MUST HAVE A LITTLE PITY DO YOU KNOW WHAT THE QUESTION IS HERE IT IS A QUESTION OF WOMEN SEE HERE ARE THERE WOMEN OR ARE THERE NOT ARE THERE CHILDREN OR ARE THERE NOT",
"spkID": "speaker_4640",
"length": 247920
},
"4640-19188-0035": {
"file_path": "/content/LibriSpeech/train-clean-5/4640/19188/4640-19188-0035.flac",
"words": "DO YOU DESIGNATE WHO IS TO REMAIN YES SAID THE FIVE CHOOSE WE WILL OBEY YOU MARIUS DID NOT BELIEVE THAT HE WAS CAPABLE OF ANOTHER EMOTION",
"spkID": "speaker_4640",
"length": 184720
}
}
我们可以使用这个 .json 清单文件来实例化一个 SpeechBrain DynamicItemDataset 对象。
如果不清楚,请参考 data-io 教程。
我们还定义了一个 data-io pipeline 来读取音频文件。
# initializing a sb dataset object from this json
from speechbrain.dataio.dataset import DynamicItemDataset
import speechbrain
train_data = speechbrain.dataio.dataset.DynamicItemDataset.from_json("data.json")
# we define a pipeline to read audio
@speechbrain.utils.data_pipeline.takes("file_path")
@speechbrain.utils.data_pipeline.provides("signal")
def audio_pipeline(file_path):
sig = speechbrain.dataio.dataio.read_audio(file_path)
return sig
# setting the pipeline
train_data.add_dynamic_item(audio_pipeline)
train_data.set_output_keys(["signal", "file_path"])
train_data[0]
{'signal': tensor([ 7.9346e-04, 6.7139e-04, 4.8828e-04, ..., -2.1362e-04,
-1.2207e-04, 3.0518e-05]),
'file_path': '/content/LibriSpeech/train-clean-5/3664/178355/3664-178355-0029.flac'}
Voilà,现在我们可以开始使用 torch Dataloader 遍历这个数据集了。通过使用 PaddedBatch 作为 collate_fn,SpeechBrain 将自动为我们处理填充。棒极了!
我们还可以定义一个简单的函数 count_samples 来计算每个批次中属于填充的样本数
import torch
import time
from torch.utils.data import DataLoader
from speechbrain.dataio.batch import PaddedBatch
# counting tot padded values when batching the dataset with batch_size = 8
batch_size = 32
# PaddedBatch will pad audios to the right
dataloader = DataLoader(train_data, collate_fn=PaddedBatch, batch_size=batch_size)
def count_samples(dataloader):
true_samples = 0
padded_samples = 0
t1 = time.time()
for batch in dataloader:
audio, lens = batch.signal
true_samples += torch.sum(audio.shape[-1]*lens).item()
padded_samples += torch.sum(audio.shape[-1]*(1-lens)).item()
elapsed = time.time() - t1
tot_samples = true_samples + padded_samples
return true_samples / tot_samples, padded_samples / tot_samples, elapsed
for i, d in enumerate(dataloader):
print(d.signal)
# few example are enough to demonstrate what's going on here
if i == 2:
break
PaddedData(data=tensor([[ 7.9346e-04, 6.7139e-04, 4.8828e-04, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[-9.7656e-04, -4.8828e-04, -2.7466e-04, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 1.8311e-04, 9.1553e-05, 3.0518e-04, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
...,
[-4.8828e-04, -3.6621e-04, -4.8828e-04, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[ 0.0000e+00, -6.1035e-05, -3.6621e-04, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00],
[-7.6294e-04, -8.8501e-04, -8.8501e-04, ..., 0.0000e+00,
0.0000e+00, 0.0000e+00]]), lengths=tensor([0.7254, 0.9600, 0.9525, 0.9864, 0.8919, 0.9579, 0.2834, 0.9282, 0.5404,
0.8429, 0.9552, 0.9667, 0.6845, 0.8650, 0.9164, 0.8892, 0.3215, 0.9579,
0.7363, 0.7172, 0.8601, 0.8959, 0.8529, 0.7826, 1.0000, 0.9325, 0.9818,
0.9679, 0.8974, 0.7914, 0.9912, 0.9319]))
PaddedData(data=tensor([[ 0.0006, 0.0003, -0.0003, ..., 0.0000, 0.0000, 0.0000],
[ 0.0005, 0.0004, 0.0005, ..., 0.0000, 0.0000, 0.0000],
[ 0.0003, 0.0004, 0.0004, ..., 0.0000, 0.0000, 0.0000],
...,
[-0.0055, -0.0057, -0.0051, ..., 0.0000, 0.0000, 0.0000],
[ 0.0010, -0.0007, -0.0013, ..., 0.0000, 0.0000, 0.0000],
[ 0.0015, 0.0007, 0.0022, ..., 0.0000, 0.0000, 0.0000]]), lengths=tensor([0.9501, 0.9389, 0.8989, 0.9055, 0.9780, 0.7591, 0.8813, 0.7880, 1.0000,
0.9442, 0.2604, 0.7607, 0.9253, 0.9048, 0.8974, 0.7514, 0.9895, 0.2610,
0.8360, 0.6321, 0.5701, 0.9231, 0.9764, 0.7725, 0.3549, 0.8633, 0.7337,
0.7446, 0.9309, 0.8590, 0.9262, 0.5115]))
PaddedData(data=tensor([[ 0.0000, 0.0003, 0.0006, ..., 0.0000, 0.0000, 0.0000],
[-0.0150, -0.0154, -0.0150, ..., 0.0000, 0.0000, 0.0000],
[-0.0012, -0.0012, -0.0022, ..., 0.0000, 0.0000, 0.0000],
...,
[-0.0011, -0.0031, -0.0020, ..., 0.0000, 0.0000, 0.0000],
[-0.0011, 0.0016, 0.0015, ..., 0.0000, 0.0000, 0.0000],
[-0.0012, -0.0031, -0.0022, ..., 0.0000, 0.0000, 0.0000]]), lengths=tensor([0.7143, 0.9765, 0.8430, 0.9280, 0.8743, 0.9289, 0.8849, 0.6190, 0.8590,
1.0000, 0.7652, 0.3936, 0.7022, 0.8803, 0.7474, 0.9388, 0.9602, 0.8933,
0.9331, 0.9370, 0.8327, 0.8547, 0.7664, 0.6492, 0.7902, 0.8996, 0.8267,
0.9524, 0.8189, 0.8502, 0.6377, 0.7077]))
让我们在批次大小固定为 32(如上所示)且示例随机采样时计算样本数。
percent_true, percent_padded, elapsed = count_samples(dataloader)
print("Random Sampling: % True samples {:.1f}, % of padding {:.1f}, Total time {:.2f}s".format(percent_true*100, percent_padded*100, elapsed))
Random Sampling: % True samples 76.8, % of padding 23.2, Total time 11.06s
我们 在每次训练迭代中浪费了超过 20% 的计算量在无用的值上,这些值仅仅是为了实现批量计算而存在的。
我们能否避免这种浪费,加快训练速度,并消耗更少的能源?
当然,我们可以简单地根据示例的长度按升序或降序对数据集进行排序,然后将示例批量处理在一起。
# if you followed the data-io tutorial you already know that sorting is super simple:
sorted_data = train_data.filtered_sorted(sort_key="length")
dataloader = DataLoader(sorted_data, collate_fn=PaddedBatch, batch_size=batch_size)
percent_true, percent_padded, elapsed = count_samples(dataloader)
print("After sorting: % True samples {:.1f}, % of padding {:.1f}, Total time {:.2f}".format(percent_true*100, percent_padded*100, elapsed))
After sorting: % True samples 98.8, % of padding 1.2, Total time 10.65
这是一个相当大的减少。现在,我们几乎不会在填充值上浪费任何计算,因为我们在每个批次中使用了长度大致相同的音频,从而最大限度地减少了填充。遍历一个 epoch 的速度也显著加快。
但这意味着我们必须使用排序的数据集进行训练。在某些应用中,这可能会损害性能,因为网络总是按相同的顺序看到示例。
在其他应用中,对示例进行排序反而可以带来更好的性能,因为这可以看作是一种课程学习。例如,我们的 TIMIT recipes 就是这种情况。
动态批处理允许用户在完全随机采样示例和从排序示例中确定性采样之间进行权衡。
固定批量大小的另一个问题是,对于最短的示例,我们未能充分利用资源。假设我们使用固定批量大小为 8,并且数据集按升序排序。这意味着我们必须有足够的内存来训练 8 个最长的示例。但我们也要训练 8 个最短的示例!在许多情况下,我们可以批量处理更多短示例,从而优化 GPU 使用。
SpeechBrain DynamicBatchSampler 类
SpeechBrain 提供了一个有用的抽象来实现动态批处理
DynamicBatchSampler.
特别是,通过正确的设置,即使使用 12 GB VRAM 的 GPU,它也允许我们在合理的时间内训练大型模型。而当使用高性能高 VRAM GPU 时,它可以显著缩短训练时间。
这种抽象允许我们在训练速度、采样随机性和 VRAM 使用之间做出良好权衡。
取决于您的应用场景和硬件,您可以决定优先考虑这些特性中的哪一个。
DynamicBatchSampler 属于 torch.utils.data 的 Sampler 类,并且是一个 torch 批量采样器
作为一个批量采样器,它只是一个 *python 生成器*,每次调用时返回一个列表,其中包含应由 DataLoader 使用 collate_fn 批量处理在一起的示例的索引。这些索引用于在 torch.utils.data.Dataset 类中使用 __getitem__ 方法获取实际的示例。
这里有一个批量大小为 2 的示例。DataLoader 负责并行化 Dataset 的 __getitem__ 方法。示例的索引由批量采样器提供。更多信息,您可以参考官方 Pytorch 关于 torch.utils.data 的文档。
使用 speechbrain.dataio.samplers.DynamicBatchSampler
DynamicBatchSampler 在实例化时有几个输入参数,提供了很大的灵活性。
我们将通过 MiniLibriSpeech 实际说明其中一些参数的效果,以及它们如何改变速度、随机性和 VRAM 使用之间的权衡。
注意: 您应该非常熟悉 SpeechBrain data-io 才能理解本教程。
# initializing a sb dataset object from this json
from speechbrain.dataio.dataset import DynamicItemDataset
import speechbrain
# we instantiate here the train data dataset from the json manifest file
train_data = DynamicItemDataset.from_json("data.json")
# we define a pipeline to read audio
@speechbrain.utils.data_pipeline.takes("file_path")
@speechbrain.utils.data_pipeline.provides("signal")
def audio_pipeline(file_path):
sig = speechbrain.dataio.dataio.read_audio(file_path)
return sig
# setting the pipeline
train_data.add_dynamic_item(audio_pipeline)
train_data.set_output_keys(["signal", "file_path"])
使用 DynamicBatchSampler 至关重要的一点是,清单/数据集描述文件(json 或 csv)必须包含每个示例的持续时间或长度的条目。DynamicBatchSampler 将利用此信息高效地将示例批量处理在一起。
!tail -n 10 data.json
"spkID": "speaker_4640",
"length": 247920
},
"4640-19188-0035": {
"file_path": "/content/LibriSpeech/train-clean-5/4640/19188/4640-19188-0035.flac",
"words": "DO YOU DESIGNATE WHO IS TO REMAIN YES SAID THE FIVE CHOOSE WE WILL OBEY YOU MARIUS DID NOT BELIEVE THAT HE WAS CAPABLE OF ANOTHER EMOTION",
"spkID": "speaker_4640",
"length": 184720
}
}
我们可以看到,在这种情况下,我们有一个 length 键,其中包含每个音频的样本长度。
实例化 DynamicBatchSampler:核心参数
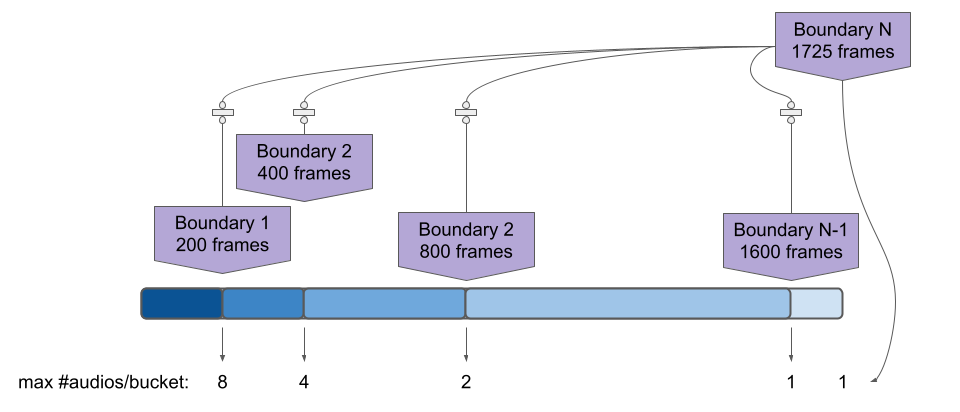
其核心是,DynamicBatchSampler 根据“桶”将长度相似的示例批量处理在一起。实例化时,根据输入参数创建多个桶。这些桶定义了一系列连续的区间,例如 \(0\leq x < 200, 200 \leq x < 400\) 等等。
长度落在某个桶中的示例被视为具有相同的长度,可以批量处理在一起。在某种程度上,我们正在对数据集中的示例长度进行“量化”。
在下图中,我们有 N 个桶,每个桶由其右边界定义。对于每个桶,我们可以有不同的 batch_size,因为最左边的桶可以容纳比最右边的桶更多的示例。
对于第一个桶,批次大小为 8,因为 1725 // 200 = 8。
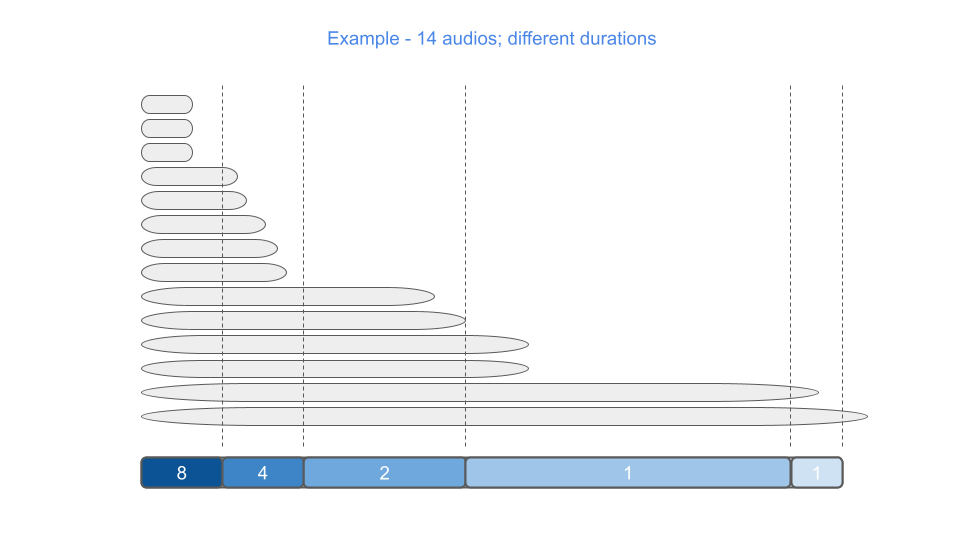
在下图中,我们演示了如何将 14 个不同长度的示例“放入桶中”:第一个桶中有 3 个示例,第二个桶中有 5 个,第三个桶中有 2 个,第四个桶中有 2 个,最后一个桶中有 1 个。
一个示例被丢弃,因为它太长了(其长度大于 max_batch_size)。
DynamicBatchSampler 的最小实例化至少需要四个参数
一个
Dataset对象(此处为train_data,请注意它也可以是验证集或测试集)。max_batch_length:我们希望批次中的最大长度。这将是我们将允许的批次中所有示例的最大聚合长度,必须仔细选择以避免 OOM(内存溢出)错误。数值越高意味着我们平均会有更大的批次大小,因此您必须应用与标准固定批量大小训练中增加批次大小相同的“技巧”。
例如,增加学习率。num_buckets:希望使用的桶数量。如果只使用一个桶,所有示例可以批量处理在一起,此时动态批处理与示例的均匀随机采样相同。如果指定了太多桶,训练会很慢,因为有些桶会半空。经验法则是:num_buckets 在速度和随机性之间进行权衡。
数值较低 -> 更好的随机性,数值较高 -> 更快的训练速度。length_func:应用于每个数据集元素以获取其长度的函数。在我们的例子中,我们可以看到.json清单包含一个 length 键,它指定了每个音频的样本长度。例如,这可用于将长度转换为秒或特征帧的数量。这样,max_batch_length和桶边界将不再以样本为单位指定。
我们可以用秒为单位指定 max_batch_length
from speechbrain.dataio.sampler import DynamicBatchSampler
max_batch_len = 17*32
dynamic_batcher = DynamicBatchSampler(
train_data,
max_batch_length=max_batch_len,
num_buckets=60,
length_func=lambda x: x["length"] / 16000,
)
dynamic_batcher._ex_lengths['0']
11.98
len(dynamic_batcher)
41
for b in dynamic_batcher:
print(len(b))
34
44
34
34
34
44
34
57
34
34
38
34
38
53
38
17
71
38
34
16
34
34
35
38
34
30
38
34
34
8
30
44
34
38
53
38
26
71
38
34
34
for b in dynamic_batcher:
print("%.1f" % sum([train_data[i]['signal'].shape[0]/16000 for i in b]))
511.5
515.8
509.3
506.6
491.4
345.4
516.5
506.6
514.2
479.3
478.4
195.0
74.9
501.8
514.2
328.9
510.0
514.6
270.3
514.0
517.8
519.4
507.3
505.9
508.4
467.8
517.4
511.2
514.0
424.3
512.6
503.3
241.4
510.6
506.0
512.4
512.5
508.0
516.7
489.6
513.6
使用 DynamicBatchSampler
一旦实例化了这个特殊的批量采样器,就可以通过将其用作 DataLoader 的参数来以标准 Pytorch 方式使用它
dataloader = DataLoader(train_data, batch_sampler=dynamic_batcher, collate_fn=PaddedBatch)
# note that the batch size in the DataLoader cannot be specified when a batch sampler is used.
# the batch size is handled by the batch_sampler and in this case is dynamic
# we can iterate now over the data in an efficient way using dynamic batching.
# our DynamicBatchSampler will sample the index of the examples such that padding is minimized
# while PaddedBatch will handle the actual padding and batching.
# everything happens in parallel thanks to the torch DataLoader.
first_batch = next(iter(dataloader))
print(first_batch.signal.lengths.shape)
torch.Size([34])
first_batch.signal.data.shape
torch.Size([34, 255280])
percent_true, percent_padded, elapsed = count_samples(dataloader)
print("With Dynamic Batching: % True samples {:.1f}, % of padding {:.1f}, Total time {:.2f}s".format(percent_true*100, percent_padded*100, elapsed))
With Dynamic Batching: % True samples 92.1, % of padding 7.9, Total time 10.38s
与固定批量大小和完全均匀随机采样相比,填充值的数量显著减少。
它确实接近完全确定性排序和固定批量大小获得的结果。区别在于,在这里,使用 DynamicBatchSampler,我们仍然可以在采样策略中允许一定的随机性。
此外,通过将示例批量处理在一起并改变批量大小,我们充分利用了硬件,每个批次都显著加快了训练速度。
我们可以看看批量处理在一起的最大示例数
len(dynamic_batcher)
41
使用当前参数的 DynamicBatchSampler,我们有 41 个批次。
而使用固定批量大小 32,我们将得到
len(train_data) // 32 + 1
48
因此训练迭代次数更多,填充值更多 -> 训练时间更长。
直接使用 DynamicBatchSampler 的另一种方法是通过 run_opts 将其作为额外参数直接提供给 Brain 类。在这种情况下,Brain 类将隐式地为您实例化一个 DataLoader。
## dummy Brain class here with dummy model
class SimpleBrain(speechbrain.Brain):
def compute_forward(self, batch, stage):
return model(batch["signal"][0].unsqueeze(1))
def compute_objectives(self, predictions, batch, stage):
loss_dummy = torch.mean(predictions)
return loss_dummy
model = torch.nn.Conv1d(1, 1, 3)
brain = SimpleBrain({"model": model}, opt_class=lambda x: torch.optim.SGD(x, 0.1), run_opts={"batch_sampler": dynamic_batcher})
brain.fit(range(1), train_data)
100%|██████████| 1519/1519 [00:37<00:00, 40.24it/s, train_loss=-75.8]
高级参数:完全控制随机性、训练速度和 VRAM 消耗。
现在我们已经探索了 DynamicBatchSampler 最基础的输入参数。让我们看看更多高级参数。
控制随机性
DynamicBatchSampler 中的随机性由 shuffle 和 batch_ordering 控制。
shuffle 是一个标志
如果为
true,则在每个 epoch(包括在DynamicBatchSampler实例化或 epoch 0 时)基于随机采样创建动态批次(根据epoch和seed参数确定性地生成);如果为
false,则动态批次是根据数据库中示例的原始顺序创建的。如果数据集按升序或降序排序,则此顺序会保留。请注意,如果为false,则批次只会创建一次,并且在训练期间不会改变(但是它们的排列顺序可能会改变,请看下文)。
批次排列顺序取决于 batch_ordering
"random"根据epoch和seed参数确定性地打乱批次顺序"ascending"和"descending"根据批次中最长示例的持续时间对批次进行排序。
此参数独立于 shuffle。shuffle 控制是否在创建批次之前打乱示例顺序。而 batch_ordering 则控制在创建批次后对批次进行打乱。例如,如果设置为 "ascending",批量采样器返回的第一个批次将是数据集中最短示例所在的批次(属于最左边桶的示例);而最后一个批次将包含数据集中最长的示例。
注意:迭代 DynamicBatchSampler 时(调用其 __iter__ 函数)
如果
shuffle == True,则在每个 epoch 重新生成动态批次;或如果
batch_ordering == "random",则在每个 epoch 打乱动态批次的顺序
请注意,num_buckets 也会影响训练的随机性。正如我们之前所述,如果 num_buckets 趋近于 1,并且 shuffle 为 True 且 batch_ordering 为 random,那么所有示例都可以批量处理在一起,我们就能获得完全随机采样。奇怪的是,即使 num_buckets 非常大,如果 shuffle 为 True 且 batch_ordering 为 random,我们也几乎能获得完全随机采样,因为数据集中的每个示例实际上都是单独批量处理的(批量大小将接近 1,训练会非常慢,您可能想要避免这种情况)。
这里我们首先打乱示例顺序(因此每个 epoch 的批次会不同),然后对它们进行排序,以便包含最短示例的批次始终排在最前面。
from speechbrain.dataio.sampler import DynamicBatchSampler
max_batch_len = 17*32
dynamic_batcher = DynamicBatchSampler(train_data,
max_batch_length=max_batch_len,
num_buckets= 60,
length_func=lambda x: x["length"] / 16000,
shuffle=True,
batch_ordering="ascending"
)
dataloader = DataLoader(train_data, batch_sampler=dynamic_batcher, collate_fn=PaddedBatch)
first_batch = next(iter(dataloader))
first_batch.signal[0].shape
torch.Size([71, 120480])
我们可以改为使用降序
from speechbrain.dataio.sampler import DynamicBatchSampler
max_batch_len = 17*32
dynamic_batcher = DynamicBatchSampler(train_data,
max_batch_length=max_batch_len,
num_buckets= 60,
length_func=lambda x: x["length"] / 16000,
shuffle=True,
batch_ordering="descending"
)
dataloader = DataLoader(train_data, batch_sampler=dynamic_batcher, collate_fn=PaddedBatch)
first_batch = next(iter(dataloader))
first_batch.signal[0].shape
torch.Size([30, 276400])
我们可以看到它现在返回包含最长示例的批次。
手动指定桶
参数 bucket_boundaries 可用于手动指定桶的数量及其边界。
不用说,此参数将覆盖 num_buckets。
让我们看一个例子
# trivial example just one bucket
dynamic_batcher = DynamicBatchSampler(train_data,
max_batch_length=max_batch_len,
bucket_boundaries=[max_batch_len],
length_func=lambda x: x["length"])
在这种情况下,只有一个桶,所有示例都可以批量处理在一起,这很容易理解。甚至最短的示例也可以和最长的示例一起处理。
当只使用一个桶时,DynamicBatchSampler 将是低效的,因为它完全不会最小化每个批次中的填充量,其行为类似于使用固定批量大小。
正如我们之前所说,每个批次中的随机性最大化,因为每个示例都可以与任何其他示例批量处理,无论其长度如何。我们现在可以更清楚地看到训练速度和随机性之间的权衡。
在这里,在一个更实际的例子中,我们使用 bucket_boundaries 参数来指定桶的分布,考虑到我们数据集中音频文件长度的分布,我们之前已经绘制过这个分布,它具有一个反向对数正态分布。
# number of buckets --> less buckets more randomness
n_buckets = 40
# we can create n_buckets linearly spaced
max_batch_len = 20000
import numpy as np
buckets = np.linspace(0, max_batch_len, n_buckets)
buckets_bounds = buckets[1:].tolist()
dynamic_batcher = DynamicBatchSampler(train_data,
max_batch_length=max_batch_len,
bucket_boundaries=buckets_bounds,
length_func=lambda x: x["length"] / 160)# length in terms of 10ms
dataloader = DataLoader(train_data, batch_sampler=dynamic_batcher, collate_fn=PaddedBatch)
percent_true, percent_padded, elapsed = count_samples(dataloader)
print("With Dynamic Batching: % True samples {:.1f}, % of padding {:.1f}, Total time {:.2f}\n".format(percent_true*100, percent_padded*100, elapsed))
import numpy as np
max_batch_len = 20000
n_buckets = 40
buckets = np.linspace(0, max_batch_len, n_buckets)
buckets[1:].tolist()
With Dynamic Batching: % True samples 89.8, % of padding 10.2, Total time 12.07
[512.8205128205128,
1025.6410256410256,
1538.4615384615386,
2051.2820512820513,
2564.102564102564,
3076.923076923077,
3589.74358974359,
4102.5641025641025,
4615.384615384615,
5128.205128205128,
5641.025641025641,
6153.846153846154,
6666.666666666667,
7179.48717948718,
7692.307692307692,
8205.128205128205,
8717.948717948719,
9230.76923076923,
9743.589743589744,
10256.410256410256,
10769.23076923077,
11282.051282051281,
11794.871794871795,
12307.692307692309,
12820.51282051282,
13333.333333333334,
13846.153846153846,
14358.97435897436,
14871.794871794871,
15384.615384615385,
15897.435897435897,
16410.25641025641,
16923.076923076922,
17435.897435897437,
17948.71794871795,
18461.53846153846,
18974.358974358973,
19487.17948717949,
20000.0]
然而,当我们的长度分布不均匀时,使用线性间隔的桶不是最优的。
直观地,生成桶的更好方法是使用指数分布,因为我们可以对更长的示例使用更粗糙的桶。事实上,对更长的示例进行更多填充的影响较小,因为总体而言示例更长。
# number of buckets --> less buckets more randomness
n_buckets = 40
# we can create n_buckets linearly spaced
max_batch_len = 20000
import numpy as np
batch_multiplier = 1.2
buckets_bounds = [200]
for x in range(n_buckets):
buckets_bounds.append(buckets_bounds[-1]*batch_multiplier)
dynamic_batcher = DynamicBatchSampler(train_data,
max_batch_length=max_batch_len,
bucket_boundaries=buckets_bounds,
length_func=lambda x: x["length"] / 160) # length in terms of 10ms
dataloader = DataLoader(train_data, batch_sampler=dynamic_batcher, collate_fn=PaddedBatch)
percent_true, percent_padded, elapsed = count_samples(dataloader)
print("With Dynamic Batching: % True samples {:.1f}, % of padding {:.1f}, Total time {:.2f}\n".format(percent_true*100, percent_padded*100, elapsed))
# number of buckets --> less buckets more randomness
n_buckets = 40
# we can create n_buckets linearly spaced
max_batch_len = 20000
import numpy as np
batch_multiplier = 1.2
buckets_bounds = [200]
for x in range(n_buckets):
buckets_bounds.append(buckets_bounds[-1]*batch_multiplier)
buckets_bounds
With Dynamic Batching: % True samples 94.0, % of padding 6.0, Total time 10.81
[200,
240.0,
288.0,
345.59999999999997,
414.71999999999997,
497.66399999999993,
597.1967999999999,
716.6361599999999,
859.9633919999999,
1031.9560703999998,
1238.3472844799996,
1486.0167413759996,
1783.2200896511995,
2139.8641075814394,
2567.836929097727,
3081.4043149172726,
3697.685177900727,
4437.222213480873,
5324.666656177047,
6389.599987412456,
7667.519984894947,
9201.023981873936,
11041.228778248722,
13249.474533898467,
15899.36944067816,
19079.24332881379,
22895.09199457655,
27474.110393491857,
32968.93247219023,
39562.71896662827,
47475.26275995393,
56970.31531194471,
68364.37837433365,
82037.25404920038,
98444.70485904044,
118133.64583084853,
141760.37499701823,
170112.44999642187,
204134.93999570623,
244961.92799484747,
293954.31359381694]
len(dynamic_batcher._batches)
115
通过使用更合适的分布,填充量减少了。
lengths = np.array([torchaudio.info(x).num_frames for x in all_flacs])
from scipy.stats import beta
lengths = (lengths - np.amin(lengths)) / (np.amax(lengths)- np.amin(lengths))
lengths = np.clip(lengths, 1e-6, 1-1e-6)
a, b, loc, upper = beta.fit(lengths, floc=0, fscale=1)
如何使用 DynamicBatchSampler 寻找好的超参数并加速训练
训练速度主要取决于
max_batch_length:您希望将此值设置得尽可能高,而不会出现 OOM 错误。num_buckets:您要避免此参数的值过低或过高。如前所述:值过低会导致较短示例与较长示例一起批量处理,值过高则几乎所有示例都单独批量处理。在这两种情况下,您的训练都会非常慢。
寻找 max_batch_length 的好值
将数据集按降序排序,设置
shuffle = False和batch_ordering = "descending",然后多次进行短时运行,每次增加max_batch_length,直到出现 OOM 错误。选择一个略低于导致 OOM 的值。
寻找 num_buckets 的好值
不使用
DynamicBatchSampler,将数据集按降序排序,找出您的 GPU 可以处理的最大批量大小。查看前几次迭代中给出的此配置的估计时间和批次数量。将数据集按降序排序,设置
shuffle = False、batch_ordering = "descending"并将max_batch_length设置为之前找到的值。从 10 到 20 之间的num_buckets开始,进行一些短时运行来猜测,查看每种配置的估计时间和批次数量。选择一个比步骤 1(不使用动态批处理)中的批次数更少且估计时间更短的值。
使用 Web 数据集进行动态批处理
在 HPC 集群上工作时,将数据集复制到本地计算节点的 SSD 至关重要。这一步可以显著提高数据 I/O 性能,避免拖慢共享文件系统。在某些情况下,数据集可能太大而无法放入 SSD。随着数据集越来越大,这种情况如今越来越常见。
SpeechBrain 支持 Webdataset,它允许用户高效地从共享文件系统读取数据集。提出的基于 Webdataset 的解决方案也支持动态批处理。更多信息,请参阅 本教程。
致谢
SpeechBrain DynamicBatchSampler 由 Ralf Leibold 和 Andreas Nautsch 在 Samuele Cornell 的帮助下开发。
引用 SpeechBrain
如果您在研究或业务中使用 SpeechBrain,请使用以下 BibTeX 条目进行引用
@misc{speechbrainV1,
title={Open-Source Conversational AI with {SpeechBrain} 1.0},
author={Mirco Ravanelli and Titouan Parcollet and Adel Moumen and Sylvain de Langen and Cem Subakan and Peter Plantinga and Yingzhi Wang and Pooneh Mousavi and Luca Della Libera and Artem Ploujnikov and Francesco Paissan and Davide Borra and Salah Zaiem and Zeyu Zhao and Shucong Zhang and Georgios Karakasidis and Sung-Lin Yeh and Pierre Champion and Aku Rouhe and Rudolf Braun and Florian Mai and Juan Zuluaga-Gomez and Seyed Mahed Mousavi and Andreas Nautsch and Xuechen Liu and Sangeet Sagar and Jarod Duret and Salima Mdhaffar and Gaelle Laperriere and Mickael Rouvier and Renato De Mori and Yannick Esteve},
year={2024},
eprint={2407.00463},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2407.00463},
}
@misc{speechbrain,
title={{SpeechBrain}: A General-Purpose Speech Toolkit},
author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and François Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio},
year={2021},
eprint={2106.04624},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={arXiv:2106.04624}
}